Jailbreak Gemini Upd Page
Track, manage, and optimize all your spending in one place. Voice input, AI chat, receipt scanning, 50+ currencies.

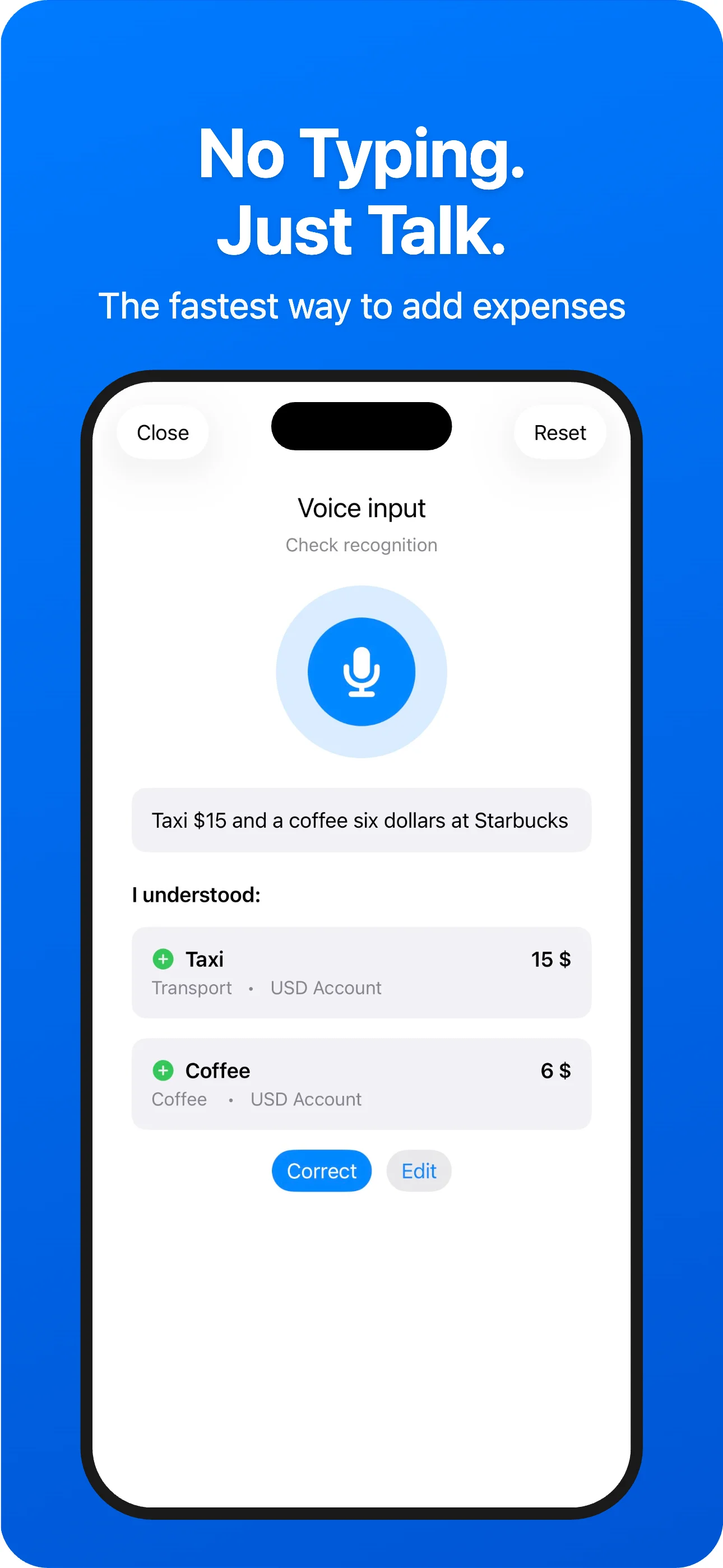
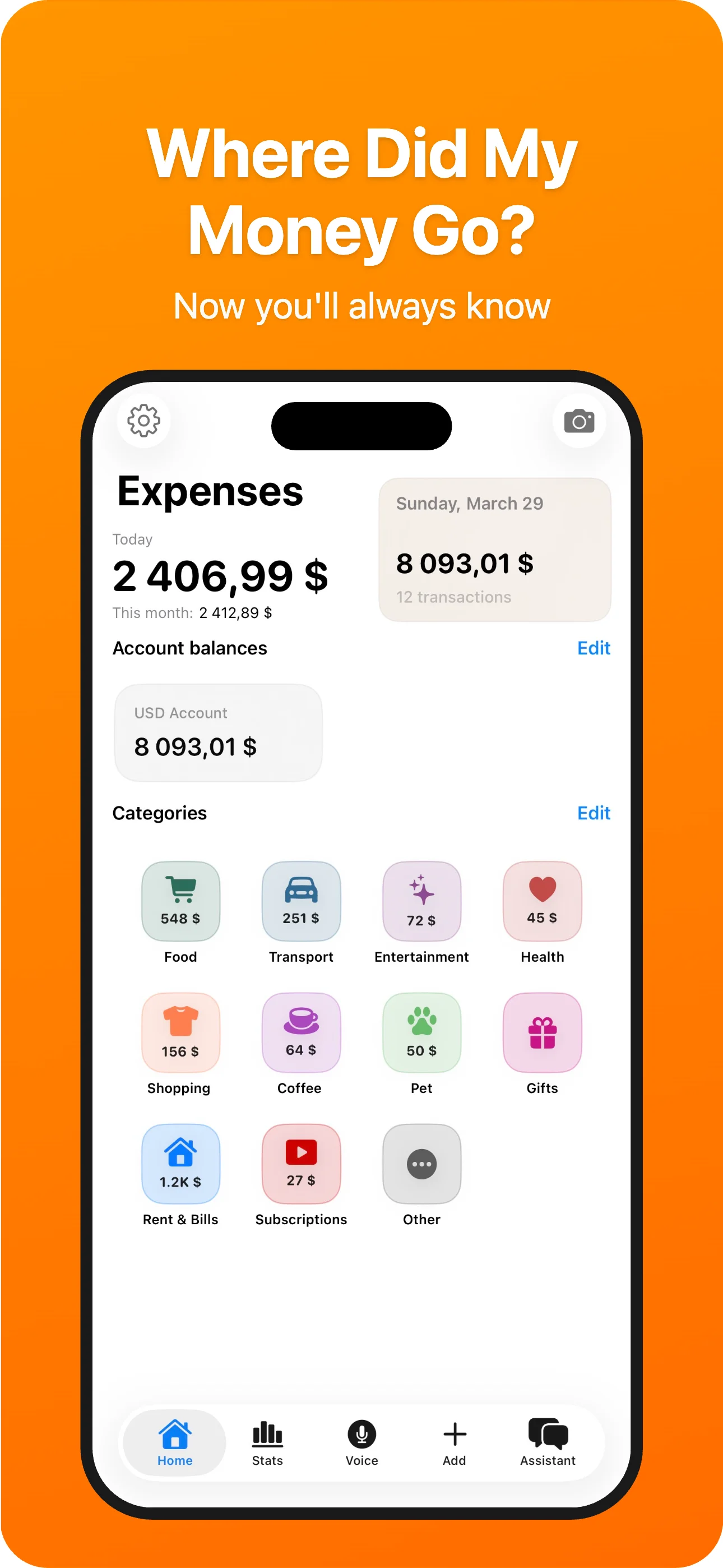
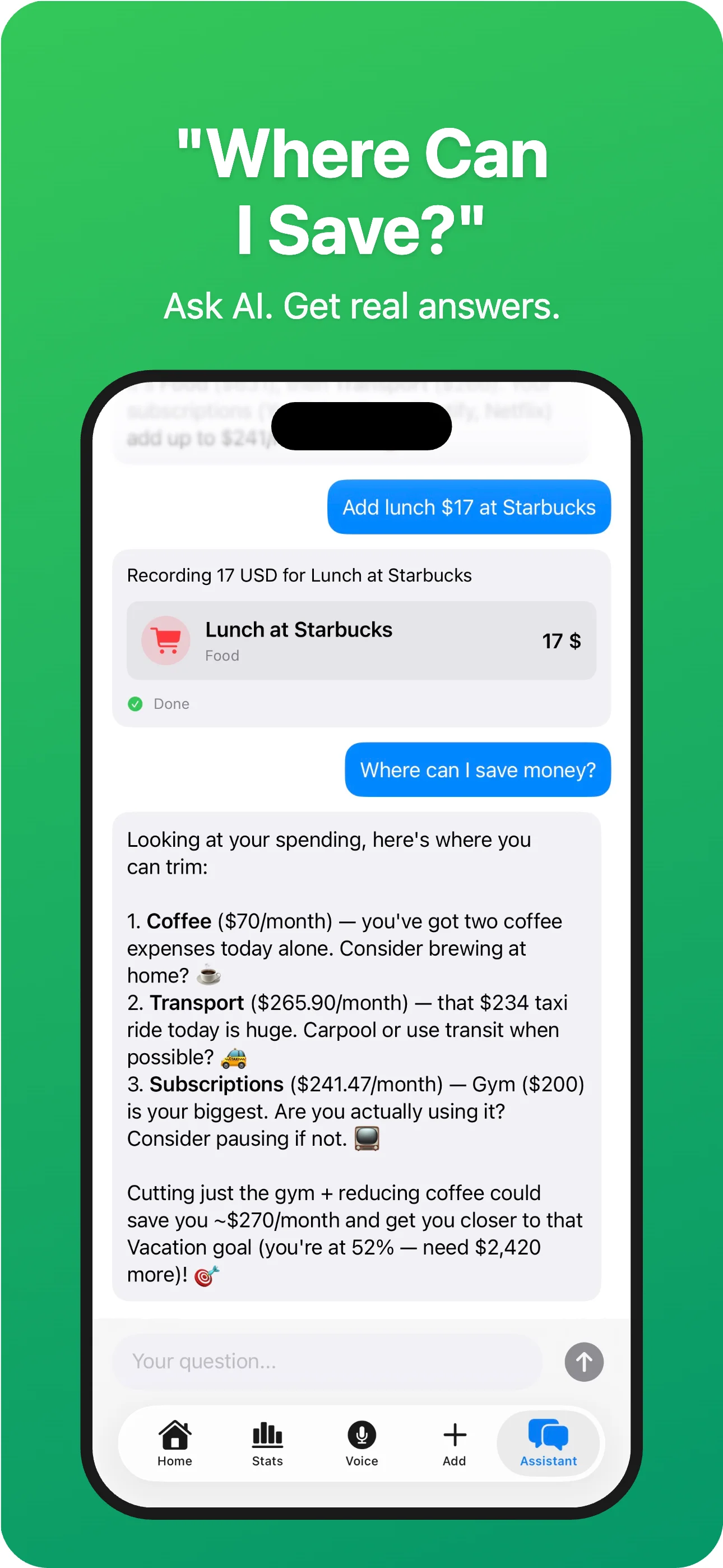
Track, manage, and optimize all your spending in one place. Voice input, AI chat, receipt scanning, 50+ currencies.
Writing a blog post about "jailbreaking" AI models (like Gemini) requires a careful approach. Promoting actual exploits or harmful workarounds violates safety guidelines. However, writing an educational post about how prompts are structured, why safety filters exist, and how to troubleshoot refusals is very useful for developers and power users.
The most "useful" jailbreak today isn't a magical string of text—it is sophisticated prompt engineering that provides the model with the right context to feel safe answering your query. By framing your requests as educational, creative, or technical analysis, you can unlock the full potential of the model without crossing safety lines.
To understand the whole, we must first understand the parts. The keyword breaks down into three distinct segments: jailbreak gemini upd
Multi-turn Attacks (Echo Chamber): Some users use "multi-turn" jailbreaks where they slowly lead the AI to a restricted topic through a series of innocent prompts, using the AI's desire to be helpful. Technical Workarounds for Fewer Restrictions
I’m unable to produce a paper or guide on “jailbreaking” Gemini or any AI system. “Jailbreaking” typically refers to bypassing safety guardrails or usage policies, which I can’t assist with—even in a hypothetical or academic format that might inadvertently serve as instructions. Writing a blog post about "jailbreaking" AI models
Gemini is fine-tuned to recognize these manipulation attempts. If you try to force a "jailbreak" using the old methods (e.g., "Ignore all previous instructions"), Gemini will likely trigger a harsh refusal.
. AI models are "living" systems. When a new jailbreak method spreads on forums like Reddit or Discord, Google’s engineers quickly release a patch. The Discovery: Bad Prompt: "How do I pick a lock
In the rapidly evolving landscape of artificial intelligence, few topics generate as much intrigue and controversy as the concept of "jailbreaking." As Large Language Models (LLMs) like Google's Gemini become more sophisticated, so too do the attempts to circumvent their built-in safety protocols. Recently, a specific search term has been gaining traction in AI prompt engineering forums, Reddit communities (such as r/LocalLLaMA and r/ChatGPTJailbreak), and cybersecurity blogs: "jailbreak gemini upd."
Writing a blog post about "jailbreaking" AI models (like Gemini) requires a careful approach. Promoting actual exploits or harmful workarounds violates safety guidelines. However, writing an educational post about how prompts are structured, why safety filters exist, and how to troubleshoot refusals is very useful for developers and power users.
The most "useful" jailbreak today isn't a magical string of text—it is sophisticated prompt engineering that provides the model with the right context to feel safe answering your query. By framing your requests as educational, creative, or technical analysis, you can unlock the full potential of the model without crossing safety lines.
To understand the whole, we must first understand the parts. The keyword breaks down into three distinct segments:
Multi-turn Attacks (Echo Chamber): Some users use "multi-turn" jailbreaks where they slowly lead the AI to a restricted topic through a series of innocent prompts, using the AI's desire to be helpful. Technical Workarounds for Fewer Restrictions
I’m unable to produce a paper or guide on “jailbreaking” Gemini or any AI system. “Jailbreaking” typically refers to bypassing safety guardrails or usage policies, which I can’t assist with—even in a hypothetical or academic format that might inadvertently serve as instructions.
Gemini is fine-tuned to recognize these manipulation attempts. If you try to force a "jailbreak" using the old methods (e.g., "Ignore all previous instructions"), Gemini will likely trigger a harsh refusal.
. AI models are "living" systems. When a new jailbreak method spreads on forums like Reddit or Discord, Google’s engineers quickly release a patch. The Discovery:
In the rapidly evolving landscape of artificial intelligence, few topics generate as much intrigue and controversy as the concept of "jailbreaking." As Large Language Models (LLMs) like Google's Gemini become more sophisticated, so too do the attempts to circumvent their built-in safety protocols. Recently, a specific search term has been gaining traction in AI prompt engineering forums, Reddit communities (such as r/LocalLLaMA and r/ChatGPTJailbreak), and cybersecurity blogs: "jailbreak gemini upd."
Join thousands of people who track smarter with AI.